« LINUX:Glusterfs - Serveurs » : différence entre les versions
Aucun résumé des modifications |
Aucun résumé des modifications |
||
| (16 versions intermédiaires par le même utilisateur non affichées) | |||
| Ligne 51 : | Ligne 51 : | ||
Si vous activez le Firewall, ce qui est recommandé, il faut y ajouter les règles suivantes sur chaque serveur: | Si vous activez le Firewall, ce qui est recommandé, il faut y ajouter les règles suivantes sur chaque serveur: | ||
-A INPUT -p tcp -m tcp --sport 24007 - | * pour le "pool" ou ensemble de machines serveurs - accès des serveurs: | ||
-A OUTPUT -p tcp -m tcp --dport 24007 - | -A INPUT -p tcp -m tcp --sport 24007 -m iprange --src-range 192.168.1.71-192.168.1.76 -m conntrack --ctstate NEW -j ACCEPT | ||
-A OUTPUT -p tcp -m tcp --dport 24007 -m iprange --dst-range 192.168.1.71-192.168.1.76 -j ACCEPT | |||
* pour le "pool" ou ensemble de machines serveurs - accès des clients: | |||
-A INPUT -p tcp -m tcp --sport 24007 -m iprange --src-range 192.168.1.81-192.168.1.82 -m conntrack --ctstate NEW -j ACCEPT | |||
* pour les "brick" ou briques - accès des serveurs: | |||
-A INPUT -p tcp -m tcp --sport 49152:60999 -m iprange --src-range 192.168.1.71-192.168.1.76 -m conntrack --ctstate NEW -j ACCEPT | |||
-A OUTPUT -p tcp -m tcp --dport 49152:60999 -m iprange --dst-range 192.168.1.71-192.168.1.76 -j ACCEPT | |||
* pour les "brick" ou briques - accès des clients: | |||
-A INPUT -p tcp -m tcp --sport 49152:60999 -m iprange --src-range 192.168.1.81-192.168.1.82 -m conntrack --ctstate NEW -j ACCEPT | |||
=Création du Pool= | =Pool de serveurs= | ||
Un "Pool" est un regroupement de machines qui servent de serveurs GlusterFs et qui vont travailler ensemble. | |||
==Création du Pool== | |||
Pour que les différents serveurs puissent travailler ensemble, il faut constituer un "Pool". | Pour que les différents serveurs puissent travailler ensemble, il faut constituer un "Pool". | ||
| Ligne 70 : | Ligne 82 : | ||
=Lister la liste des serveurs du pool= | ==Lister la liste des serveurs du pool== | ||
Pour vérifier que tout s'est bien passé, la commande suivante exécutée sur n'importe quel serveur, permet de récupérer la liste des serveurs du "Pool": | Pour vérifier que tout s'est bien passé, la commande suivante exécutée sur n'importe quel serveur, permet de récupérer la liste des serveurs du "Pool": | ||
gluster peer status | gluster peer status | ||
| Ligne 99 : | Ligne 111 : | ||
=Connexions réseaux= | ==Connexions réseaux== | ||
On peut constater l'ouverture des communications au travers du réseau avec la commande suivante: | On peut constater l'ouverture des communications au travers du réseau avec la commande suivante: | ||
netstat -natp | grep gluster | netstat -natp | grep gluster | ||
| Ligne 119 : | Ligne 131 : | ||
=Détacher un serveur du Pool= | ==Détacher un serveur du Pool== | ||
On peut faire l'opération inverse: enlever un serveur du "Pool" avec la commande suivante, ici le serveur "sv6.home.dom": | On peut faire l'opération inverse: enlever un serveur du "Pool" avec la commande suivante, ici le serveur "sv6.home.dom": | ||
gluster peer detach sv6.home.dom | gluster peer detach sv6.home.dom | ||
| Ligne 141 : | Ligne 153 : | ||
==Matériel== | ==Matériel== | ||
Pour nos essais, nous avons placé sur chaque serveur deux nouveaux disques que nous avons | Pour nos essais, nous avons placé sur chaque serveur deux nouveaux disques avec une seule partition que nous avons formatée en XFS; nous aurions pu utiliser LVM avant le formatage en XFS. Nous utiliserons principalement le premier disque se nomme "/disk1"; le second se nomme "/disk2"; il ne sera que peu utilisé. Nous y créerons plusieurs volumes mais dans la pratique, il est conseillé pour une question simple de gestion d'avoir des disques de même taille et qu'ils ne soient utilisés que par un seul volume. Dans le cas contraire, nous aurons des problèmes de débordements car Glusterfs essaie de répartir les fichiers de façon équitables. Il existe une option de gestion de quotas. | ||
Sur chacun de ces disques, nous créons un répertoire "glusterfs". Ce nom peut être nommé selon vos désirs. | Sur chacun de ces disques, nous créons un répertoire "glusterfs". Ce nom peut être nommé selon vos désirs. | ||
| Ligne 149 : | Ligne 161 : | ||
==[[LINUX:Glusterfs - Type Distribué|Type Distribué]]== | ==[[LINUX:Glusterfs - Type Distribué|Type Distribué]]== | ||
Ce premier type '''distribué''' correspond au '''RAID0'''. Les fichiers sont distribués sur les divers espaces disques individuels des machines du cluster. Cette répartition tend à être équitable entre les disques. Il n'y a pas de doublons. | Ce premier type '''distribué''' correspond au '''RAID0'''. Les fichiers sont distribués sur les divers espaces disques individuels des machines du cluster. Cette répartition tend à être équitable entre les disques. Il n'y a pas de doublons de fichier. | ||
==[[LINUX:Glusterfs - Type Répliqué|Type Répliqué]]== | ==[[LINUX:Glusterfs - Type Répliqué|Type Répliqué]]== | ||
Ce second type '''répliqué''' correspond au '''RAID1'''. Les fichiers sont distribués sur les divers espaces disques individuels des machines du cluster. | Ce second type '''répliqué''' correspond au '''RAID1'''. Les fichiers sont distribués sur les divers espaces disques individuels des machines du cluster. Chaque espace disque accueille tous les fichiers. Ils sont tous en doublons. | ||
Chaque espace disque accueille tous les fichiers. | |||
==[[LINUX:Glusterfs - Type Distribué-Répliqué|Type Distribué-Répliqué]]== | |||
Ce troisième type '''distribué-répliqué''' correspond au '''RAID10'''. Les fichiers sont distribués sur les divers espaces disques individuels des machines du cluster. C'est une combinaison des deux types précédents. | |||
==[[LINUX:Glusterfs - Type Dispersé|Type Dispersé]]== | |||
Ce quatrième type '''dispersé''' correspond au '''RAID6'''. Les fichiers sont distribués sur les divers espaces disques individuels des machines du cluster. Chaque fichier est découpé en morceaux égaux ou blocs, le dernier est complété par du vide et il y a un ou plusieurs blocs de contrôle. | |||
Chaque espace disque accueille à tour de rôle un de ces blocs. | |||
==[[LINUX:Glusterfs - Type Distribué-Dispersé|Type Distribué-Dispersé]]== | |||
Ce cinquième type '''distribué-dispersé''' correspond au '''RAID60'''. Les fichiers sont distribués sur les divers espaces disques individuels des machines du cluster. Chaque fichier est découpé en morceaux égaux ou blocs, le dernier est complété par du vide et il y a un ou plusieurs blocs de contrôle. Chaque espace disque accueille à tour de rôle un de ces blocs. C'est une combinaison du type précédent et du type "distribué" vu plus haut. | |||
==Arrêt d'un volume== | |||
Avant de pouvoir éliminer un volume, il faut l'arrêter. | |||
On effectue cette opération à partir d'une des machines du cluster et va impacter toutes les machines impliquées par le volume. | |||
La commande suivante va arrêter le volume "diskgfs1": | |||
gluster volume stop diskgfs1 | |||
==Elimination d'un volume== | |||
Maintenant que le volume est arrêté, on peut le détruire. | |||
On effectue cette opération à partir d'une des machines du cluster et va impacter toutes les machines impliquées par le volume. | |||
La commande suivante va arrêter le volume "diskgfs1": | |||
gluster volume delete diskgfs1 | |||
La destruction d'un volume n'efface pas les fichiers et répertoires concerné. | |||
Dès que ce volume est détruit, on peut effacer ces fichiers et répertoires sur les différentes machines anciennement concernées par ce volume. On ne le fait pas avant. | |||
Pour notre exemple, on détruit: | |||
* le répertoire "/disk1/glusterfs/brique1" sur la machine "sv1.home.dom" | |||
* le répertoire "/disk1/glusterfs/brique1" sur la machine "sv2.home.dom" | |||
==Liste des paramètres== | |||
La commande suivante, appliquée au volume "diskgfs1", permet de lister tous les paramètres de ce volume: | |||
gluster volume get diskgfs1 all | |||
==Modification de paramètre== | |||
Il se peut que vous désiriez changer un paramètre d'un volume. | |||
Dans l'exemple suivant, appliquée au volume "diskgfs1", on veut changer la paramètre "network.ping-timeout" et lui attribuer la valeur de "10": | |||
gluster volume set diskgfs1 network.ping-timeout 10 | |||
==Sécurité== | |||
Un paramètre intéressant permet de restreindre l'accès à un volume. | |||
Dans l'exemple suivant, appliquée au volume "diskgfs1", on veut limiter l'accès aux machines du sous-réseau "192.168.1.0/24": | |||
gluster volume set diskgfs1 auth.allow 192.168.1.0/24 | |||
==Gestion automatique des problèmes== | |||
Normalement le système règle automatiquement les problèmes courants en dehors d'un problème physique d'un disque. Si par exemple, une des machines du cluster n'est pas démarrée ou n'est pas joignable suite à une coupure réseau, la distribution des fichiers se rétablira dès son retour en activité. | |||
Outre les commandes déjà vues, on peut éventuellement dépister quelques problèmes par la commande suivante, ici pour le volume "diskgfs1": | |||
gluster volume heal diskgfs1 info summary | |||
qui donne: | |||
---- | |||
Brick sv1.home.dom:/disk1/glusterfs/brique1 | |||
Status: Connected | |||
Total Number of entries: 0 | |||
Number of entries in heal pending: 0 | |||
Number of entries in split-brain: 0 | |||
Number of entries possibly healing: 0 | |||
| |||
Brick sv2.home.dom:/disk1/glusterfs/brique1 | |||
Status: Connected | |||
Total Number of entries: 0 | |||
Number of entries in heal pending: 0 | |||
Number of entries in split-brain: 0 | |||
Number of entries possibly healing: 0 | |||
---- | |||
Dernière version du 14 juin 2023 à 11:27
But
Tout d'abord nous allons configurer les serveurs qui vont travailler ensemble.
A tout moment, il est possible d'adapter cette structure sans perturber son fonctionnement. On peut ajouter ou supprimer un serveur du "pool". On peut ajouter, supprimer, étendre, migrer, restreindre chaque ressource disque.
Nous nous cantonnerons à la création du "pool" et des ressources.
Matériel et adressage IP
Pour ces exercices, nous avons besoin de six machines. Le schéma ci-dessous reprend la connectique, le nom des machines Linux et leur adressage IP.
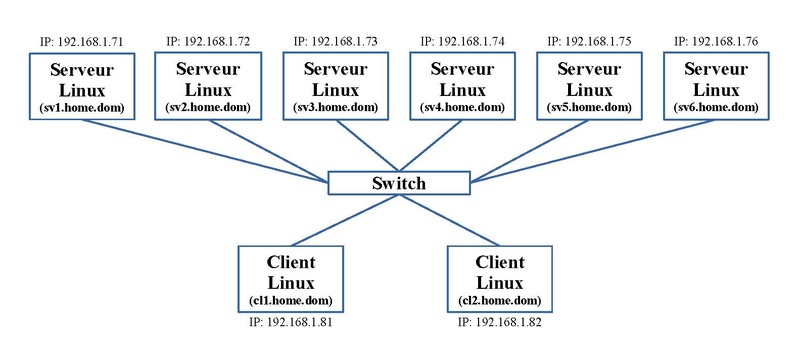
Sur chaque machine du cluster, on ajoute un nom aux différentes adresses réseaux afin quelles se reconnaissent entre elles. On le fait en local dans le fichier "/etc/hosts" suivant le schéma ci-dessus. Son contenu devient:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.1.71 sv1.home.dom 192.168.1.72 sv2.home.dom 192.168.1.73 sv3.home.dom 192.168.1.74 sv4.home.dom 192.168.1.75 sv5.home.dom 192.168.1.76 sv6.home.dom
Notons qu'on peut faire cette opération au travers de notre DNS si nous en disposons.
Installation
La première étape consiste à installer sur tous nos serveurs ("sv1.home.dom" à "sv6.home.dom") le paquet suivant:
dnf install glusterfs-server
Fichiers de configuration
Les fichiers de configuration se retrouvent dans le répertoire "/etc/glusterfs". Nous n'y avons effectué aucune modification.
Après le premier lancement du service Glusterd, le répertoire "/var/lib/glusterd" contient nombre de paramètres qui s'amendent en fonction des machines du cluster et des ressources disques. Ces paramètres sont modifiables via des lignes de commandes.
Activation et lancement du service
Il faut activer et lancer le service "glusterd.service" sur chaque serveur:
systemctl enable glusterd.service systemctl start glusterd.service
Configurer le mur de feu ou FireWall
Chaque serveur écoute sur le port TCP 24007. Quand le "pool" sera constitué, chaque serveur du cluster va entrer en communication entre eux et par la suite, les machines clients feront de même.
Si vous activez le Firewall, ce qui est recommandé, il faut y ajouter les règles suivantes sur chaque serveur:
- pour le "pool" ou ensemble de machines serveurs - accès des serveurs:
-A INPUT -p tcp -m tcp --sport 24007 -m iprange --src-range 192.168.1.71-192.168.1.76 -m conntrack --ctstate NEW -j ACCEPT -A OUTPUT -p tcp -m tcp --dport 24007 -m iprange --dst-range 192.168.1.71-192.168.1.76 -j ACCEPT
- pour le "pool" ou ensemble de machines serveurs - accès des clients:
-A INPUT -p tcp -m tcp --sport 24007 -m iprange --src-range 192.168.1.81-192.168.1.82 -m conntrack --ctstate NEW -j ACCEPT
- pour les "brick" ou briques - accès des serveurs:
-A INPUT -p tcp -m tcp --sport 49152:60999 -m iprange --src-range 192.168.1.71-192.168.1.76 -m conntrack --ctstate NEW -j ACCEPT -A OUTPUT -p tcp -m tcp --dport 49152:60999 -m iprange --dst-range 192.168.1.71-192.168.1.76 -j ACCEPT
- pour les "brick" ou briques - accès des clients:
-A INPUT -p tcp -m tcp --sport 49152:60999 -m iprange --src-range 192.168.1.81-192.168.1.82 -m conntrack --ctstate NEW -j ACCEPT
Pool de serveurs
Un "Pool" est un regroupement de machines qui servent de serveurs GlusterFs et qui vont travailler ensemble.
Création du Pool
Pour que les différents serveurs puissent travailler ensemble, il faut constituer un "Pool".
On se place sur un des serveurs et grâce à la commande suivante, on va ajouter un des autres serveurs à le rejoindre.
Dans notre exemple, on s'est placé sur la machine "sv1.home.dom" et on lui ajoute la machine "sv2.home.dom":
gluster peer probe sv2.home.dom
On fait de même pour les autres serveurs:
gluster peer probe sv3.home.dom gluster peer probe sv4.home.dom gluster peer probe sv5.home.dom gluster peer probe sv6.home.dom
Cette opération n'est pas à effectuer sur les autres serveurs.
Lister la liste des serveurs du pool
Pour vérifier que tout s'est bien passé, la commande suivante exécutée sur n'importe quel serveur, permet de récupérer la liste des serveurs du "Pool":
gluster peer status
qui donne à partir de la machine "sv1.home.dom":
Number of Peers: 5 Hostname: sv2.home.dom Uuid: d2d834b7-96e7-49a1-a178-9aa54bc74426 State: Peer in Cluster (Connected) Hostname: sv3.home.dom Uuid: 27bd8184-14c8-4176-987d-db0a03fc6993 State: Peer in Cluster (Connected) Hostname: sv4.home.dom Uuid: 3dc268fd-cc74-4072-b454-c6a26240fdf7 State: Peer in Cluster (Connected) Hostname: sv5.home.dom Uuid: ba63e02a-8dd2-4324-a8e6-16a59855378f State: Peer in Cluster (Connected) Hostname: sv6.home.dom Uuid: 15f5b1c0-f4c6-4f98-93c4-d539a4cf3873 State: Peer in Cluster (Connected)
Connexions réseaux
On peut constater l'ouverture des communications au travers du réseau avec la commande suivante:
netstat -natp | grep gluster
qui donne:
tcp 0 0 0.0.0.0:24007 0.0.0.0:* LISTEN 1215/glusterd tcp 0 0 192.168.1.71:24007 192.168.1.72:49151 ESTABLISHED 1215/glusterd tcp 0 0 192.168.1.71:24007 192.168.1.73:49151 ESTABLISHED 1215/glusterd tcp 0 0 192.168.1.71:24007 192.168.1.74:49151 ESTABLISHED 1215/glusterd tcp 0 0 192.168.1.71:24007 192.168.1.75:49151 ESTABLISHED 1215/glusterd tcp 0 0 192.168.1.71:24007 192.168.1.76:49151 ESTABLISHED 1215/glusterd tcp 0 0 192.168.1.71:49151 192.168.1.72:24007 ESTABLISHED 1215/glusterd tcp 0 0 192.168.1.71:49150 192.168.1.73:24007 ESTABLISHED 1215/glusterd tcp 0 0 192.168.1.71:49149 192.168.1.74:24007 ESTABLISHED 1215/glusterd tcp 0 0 192.168.1.71:49148 192.168.1.75:24007 ESTABLISHED 1215/glusterd tcp 0 0 192.168.1.71:49147 192.168.1.76:24007 ESTABLISHED 1215/glusterd
On remarque que les connexions se font dans les deux sens avec toutes les machines du cluster. Ceci se répète sur toutes les machines concernées.
Détacher un serveur du Pool
On peut faire l'opération inverse: enlever un serveur du "Pool" avec la commande suivante, ici le serveur "sv6.home.dom":
gluster peer detach sv6.home.dom
On le fait à partir d'une machine du pool.
Attention: Il est impératif que ce serveur qu'on élimine, ne participe à aucune ressource disque du pool.
Gestion des ressources disques
Maintenant que le "Pool" des serveurs est constitué, il faut créer les ressources disques. Ces ressources sont organisées de différentes façons; nous allons les passer en revue.
Principe
Le principe pour créer une ressource consiste a créer un ensemble d'espaces disques individuels sur certains des serveurs du cluster. Cet ensemble d'espaces disques individuels forme un volume. Dans ce volume on va y placer des fichiers. Ces fichiers seront répartis de différentes façons dans les différents espaces disques individuels. Nous sommes donc en présence d'un système de fichiers distribués au travers du réseau.
Les systèmes de répartitions a de nombreuses analogies avec le système de gestion des disques en RAID. Mais il y a plusieurs différences dont en voici deux principales:
- Le RAID se cantonne sur une seule machine, Glusterfs s'étend sur plusieurs machines du réseau
- Le RAID se déroule au bas niveau du bloc des disques, Glusterfs travaille au niveau du fichier ou de morceaux de fichiers
Une ressource est nommée volume. Un volume correspond a un ensemble d'espaces disques individuels se trouvant sur diverses machines du cluster.
Matériel
Pour nos essais, nous avons placé sur chaque serveur deux nouveaux disques avec une seule partition que nous avons formatée en XFS; nous aurions pu utiliser LVM avant le formatage en XFS. Nous utiliserons principalement le premier disque se nomme "/disk1"; le second se nomme "/disk2"; il ne sera que peu utilisé. Nous y créerons plusieurs volumes mais dans la pratique, il est conseillé pour une question simple de gestion d'avoir des disques de même taille et qu'ils ne soient utilisés que par un seul volume. Dans le cas contraire, nous aurons des problèmes de débordements car Glusterfs essaie de répartir les fichiers de façon équitables. Il existe une option de gestion de quotas.
Sur chacun de ces disques, nous créons un répertoire "glusterfs". Ce nom peut être nommé selon vos désirs.
Attention: Il ne faut jamais y placer des fichiers, les détruire, les modifier directement à partir du serveur. L'interaction avec ces ressources disques ne peut se faire qu'à partir des clients. On peut consulter leurs contenus par curiosité. Ce n'est que quand le volume est détruit au niveau de Glusterfs que l'on peut détruire son contenu. Je conseille de le détruire dans ce cas afin de pouvoir réutiliser cet espace disque pour un nouveau volume.
Type Distribué
Ce premier type distribué correspond au RAID0. Les fichiers sont distribués sur les divers espaces disques individuels des machines du cluster. Cette répartition tend à être équitable entre les disques. Il n'y a pas de doublons de fichier.
Type Répliqué
Ce second type répliqué correspond au RAID1. Les fichiers sont distribués sur les divers espaces disques individuels des machines du cluster. Chaque espace disque accueille tous les fichiers. Ils sont tous en doublons.
Type Distribué-Répliqué
Ce troisième type distribué-répliqué correspond au RAID10. Les fichiers sont distribués sur les divers espaces disques individuels des machines du cluster. C'est une combinaison des deux types précédents.
Type Dispersé
Ce quatrième type dispersé correspond au RAID6. Les fichiers sont distribués sur les divers espaces disques individuels des machines du cluster. Chaque fichier est découpé en morceaux égaux ou blocs, le dernier est complété par du vide et il y a un ou plusieurs blocs de contrôle. Chaque espace disque accueille à tour de rôle un de ces blocs.
Type Distribué-Dispersé
Ce cinquième type distribué-dispersé correspond au RAID60. Les fichiers sont distribués sur les divers espaces disques individuels des machines du cluster. Chaque fichier est découpé en morceaux égaux ou blocs, le dernier est complété par du vide et il y a un ou plusieurs blocs de contrôle. Chaque espace disque accueille à tour de rôle un de ces blocs. C'est une combinaison du type précédent et du type "distribué" vu plus haut.
Arrêt d'un volume
Avant de pouvoir éliminer un volume, il faut l'arrêter.
On effectue cette opération à partir d'une des machines du cluster et va impacter toutes les machines impliquées par le volume.
La commande suivante va arrêter le volume "diskgfs1":
gluster volume stop diskgfs1
Elimination d'un volume
Maintenant que le volume est arrêté, on peut le détruire.
On effectue cette opération à partir d'une des machines du cluster et va impacter toutes les machines impliquées par le volume.
La commande suivante va arrêter le volume "diskgfs1":
gluster volume delete diskgfs1
La destruction d'un volume n'efface pas les fichiers et répertoires concerné. Dès que ce volume est détruit, on peut effacer ces fichiers et répertoires sur les différentes machines anciennement concernées par ce volume. On ne le fait pas avant.
Pour notre exemple, on détruit:
- le répertoire "/disk1/glusterfs/brique1" sur la machine "sv1.home.dom"
- le répertoire "/disk1/glusterfs/brique1" sur la machine "sv2.home.dom"
Liste des paramètres
La commande suivante, appliquée au volume "diskgfs1", permet de lister tous les paramètres de ce volume:
gluster volume get diskgfs1 all
Modification de paramètre
Il se peut que vous désiriez changer un paramètre d'un volume.
Dans l'exemple suivant, appliquée au volume "diskgfs1", on veut changer la paramètre "network.ping-timeout" et lui attribuer la valeur de "10":
gluster volume set diskgfs1 network.ping-timeout 10
Sécurité
Un paramètre intéressant permet de restreindre l'accès à un volume.
Dans l'exemple suivant, appliquée au volume "diskgfs1", on veut limiter l'accès aux machines du sous-réseau "192.168.1.0/24":
gluster volume set diskgfs1 auth.allow 192.168.1.0/24
Gestion automatique des problèmes
Normalement le système règle automatiquement les problèmes courants en dehors d'un problème physique d'un disque. Si par exemple, une des machines du cluster n'est pas démarrée ou n'est pas joignable suite à une coupure réseau, la distribution des fichiers se rétablira dès son retour en activité.
Outre les commandes déjà vues, on peut éventuellement dépister quelques problèmes par la commande suivante, ici pour le volume "diskgfs1":
gluster volume heal diskgfs1 info summary
qui donne:
Brick sv1.home.dom:/disk1/glusterfs/brique1 Status: Connected Total Number of entries: 0 Number of entries in heal pending: 0 Number of entries in split-brain: 0 Number of entries possibly healing: 0 Brick sv2.home.dom:/disk1/glusterfs/brique1 Status: Connected Total Number of entries: 0 Number of entries in heal pending: 0 Number of entries in split-brain: 0 Number of entries possibly healing: 0