« LINUX:Glusterfs » : différence entre les versions
Aucun résumé des modifications Balise : Révoqué |
Aucun résumé des modifications |
||
| (11 versions intermédiaires par le même utilisateur non affichées) | |||
| Ligne 1 : | Ligne 1 : | ||
---- | ---- | ||
''→ [[LINUX:Notions de gestion des disques|retour à la gestion des disques]]'' | ''→ [[LINUX:Notions de gestion des disques|retour à la gestion des disques]]'' | ||
''→ [[LINUX:Haute disponibilité|retour au menu de la Haute disponibilité]]'' | ''→ [[LINUX:Haute disponibilité|retour au menu de la Haute disponibilité]]'' | ||
---- | ---- | ||
| Ligne 23 : | Ligne 23 : | ||
=[[LINUX:Glusterfs - Clients|Clients]]= | |||
Maintenant que les serveurs sont configurés, on passe à l'utilisation de ses ressources par les clients. | |||
=Référence= | |||
Pour avoir une documentation complète, consultez le site de Red-Hat: <nowiki>https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3.5/html/administration_guide/chap-red_hat_storage_architecture_and_concepts</nowiki>. Ce n'est pas la dernière version. Il y en a beaucoup d'autres sur Internet. | |||
| Ligne 32 : | Ligne 37 : | ||
---- | ---- | ||
''→ [[LINUX:Notions de gestion des disques|retour à la gestion des disques]]'' | ''→ [[LINUX:Notions de gestion des disques|retour à la gestion des disques]]'' | ||
''→ [[LINUX:Haute disponibilité|retour au menu de la Haute disponibilité]]'' | ''→ [[LINUX:Haute disponibilité|retour au menu de la Haute disponibilité]]'' | ||
---- | ---- | ||
__NOEDITSECTION__ | __NOEDITSECTION__ | ||
__FORCETOC__ | |||
[[Category:LINUX]] | [[Category:LINUX]] | ||
Dernière version du 15 juin 2023 à 17:20
→ retour à la gestion des disques
→ retour au menu de la Haute disponibilité
But
GlusterFS est un système de fichiers distribué, modulable à volonté, qui réunit les éléments de stockage de plusieurs serveurs pour former un système de fichiers uniforme. Il est adapté aux tâches gourmandes en données telles que le stockage en nuage. Il est extensible à volonté. Il contribue en outre à la haute disponibilité. Le modèle est de type Client/Serveur. Nous allons aborder en premier le côté serveur. Pour la partie client, il existe plusieurs approches.
Principe
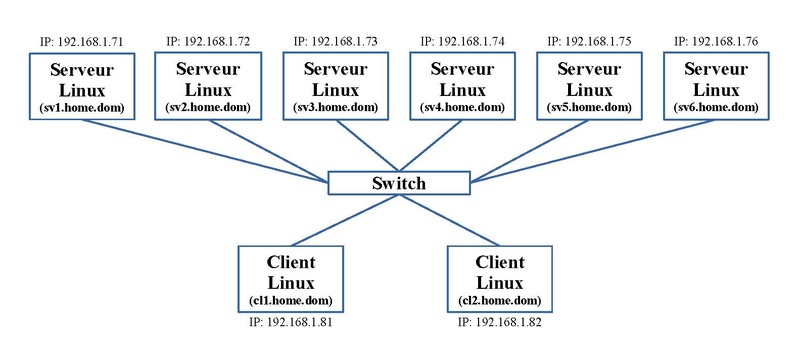
On installe les paquets nécessaires sur un ensemble de machines. Dans le schéma ci-dessous, nous avons utilisé 6 machines (partie supérieure) nommées de "sv1.home.dom" à "sv6.home.dom". Ces machines sont alors regroupées en un "pool" qui forment un cluster. On peut alors créer des ressources disques distribuées.
Tout client ("cl1.home.dom" et "cl2.home.dom" dans notre exemple) pourra alors se connecter à n'importe quel serveur du "pool" pour pourvoir utiliser la ressource désirée. Sur ces clients, il est aussi nécessaire d'installer les paquets adaptés à la technique désirée.
Serveurs
Tout d'abord nous allons configurer les serveurs qui vont travailler ensemble.
Clients
Maintenant que les serveurs sont configurés, on passe à l'utilisation de ses ressources par les clients.
Référence
Pour avoir une documentation complète, consultez le site de Red-Hat: https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3.5/html/administration_guide/chap-red_hat_storage_architecture_and_concepts. Ce n'est pas la dernière version. Il y en a beaucoup d'autres sur Internet.
→ retour à la gestion des disques
→ retour au menu de la Haute disponibilité