|
|
| (28 versions intermédiaires par le même utilisateur non affichées) |
| Ligne 3 : |
Ligne 3 : |
| ---- | | ---- |
| =But= | | =But= |
| Toute autre approche, au lieu qu'un des serveurs soit en attente sans rien faire, les serveurs se répartissent la charge et se partagent les données. Une des machines est chargée de faire le partage équitablement. En anglais, on parle de Loadbalancing. | | Toute autre approche, au lieu qu'un des serveurs soit en attente sans rien faire, les serveurs se répartissent la charge et se partagent les données. Une des machines est chargée de faire le partage équitablement. En anglais, on parle de Loadbalancing. Nous utilisons la configuration "Masquerading de NAT". |
|
| |
|
|
| |
|
| Ligne 9 : |
Ligne 9 : |
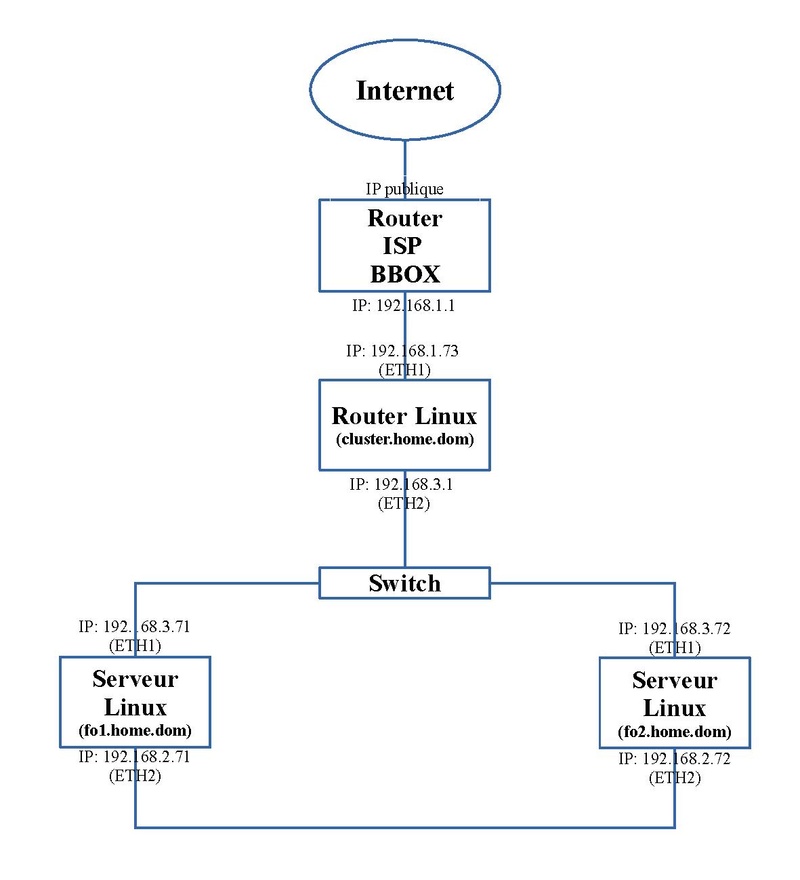
| La configuration est proche de celle présentée dans l'article sur les [[LINUX:Pacemaker - Serveurs en Failover|Serveurs en Failover]]. Comme présentée sur le schéma ci-dessous, les deux serveurs sont presque identiques à l'article précédent excepté quelques détails. Par contre l'adresse virtuelle "192.168.1.73" et le nom virtuel "cluster.home.dom" est transporté sur une troisième machine qui joue le rôle de router et comme répartiteur de charge. Il repère les services actifs sur les serveurs du cluster et, en fonction de quotas, renvoie les requêtes des clients vers un serveur qui a le moins de travail. | | La configuration est proche de celle présentée dans l'article sur les [[LINUX:Pacemaker - Serveurs en Failover|Serveurs en Failover]]. Comme présentée sur le schéma ci-dessous, les deux serveurs sont presque identiques à l'article précédent excepté quelques détails. Par contre l'adresse virtuelle "192.168.1.73" et le nom virtuel "cluster.home.dom" est transporté sur une troisième machine qui joue le rôle de router et comme répartiteur de charge. Il repère les services actifs sur les serveurs du cluster et, en fonction de quotas, renvoie les requêtes des clients vers un serveur qui a le moins de travail. |
|
| |
|
| [[FILE:LINUX:Loadbalancing.pdf|800px|center]] | | [[FILE:LINUX:Loadbalancing.masq.pdf|800px|center]] |
|
| |
|
| Pour cette mise en place, deux grandes parties sont à considérer: | | Pour cette mise en place, deux grandes parties sont à considérer: |
| Ligne 20 : |
Ligne 20 : |
|
| |
|
| ==Configurations de départ== | | ==Configurations de départ== |
| On démarre avec les configurations présentées mors de l'article sur les [[LINUX:Pacemaker - Serveurs en Failover|Serveurs en Failover]]. Quelques adaptations y seront apportée. | | On démarre avec les configurations présentées lors de l'article sur les [[LINUX:Pacemaker - Serveurs en Failover|Serveurs en Failover]]. Quelques adaptations y seront apportée. |
|
| |
|
| L'adressage doit correspondre au schéma ci-dessus. | | L'adressage doit correspondre au schéma ci-dessus. |
| Ligne 45 : |
Ligne 45 : |
|
| |
|
|
| |
|
| ==Routage== | | =[[LINUX:Loadbalancing - Serveurs du cluster (masq)|Serveurs du cluster]]= |
| Nous sommes en présence de deux LANs interconnectés par un router. Pour mettre en oeuvre correctement les différents aspects du routage; voyez l'article sur le [[LINUX:Routage statique|Routage statique]] et spécialement le chapitre sur le "Second réseau privé".
| |
| | |
| | |
| ==Activation du routage==
| |
| Il faut activer le routage sur le router "cluster.home.dom" en ajoutant un fichier, par exemple "router.conf", dans le répertoire "/etc/sysctl.d". Ce fichier doit contenir la ligne:
| |
| ----
| |
| net.ipv4.ip_forward = 1
| |
| ----
| |
| On active cette configuration soit en redémarrant la machine, soit avec la commande suivante:
| |
| sysctl -p /etc/sysctl.d/router.conf
| |
| | |
| | |
| | |
| =Configuration des serveurs du cluster=
| |
| Pour cette configuration, plusieurs pièces la composent et vont subir quelques transformations par rapport à l'article sur les [[LINUX:Pacemaker - Serveurs en Failover|Serveurs en Failover]]. Pour pouvoir utiliser une ressource disque partagée par deux machines en accès total, il faut changer de système de formatage. Or le système choisi nécessite que les deux espaces soient accessibles. Nombre de ces changements en sont la conséquence. | | Pour cette configuration, plusieurs pièces la composent et vont subir quelques transformations par rapport à l'article sur les [[LINUX:Pacemaker - Serveurs en Failover|Serveurs en Failover]]. Pour pouvoir utiliser une ressource disque partagée par deux machines en accès total, il faut changer de système de formatage. Or le système choisi nécessite que les deux espaces soient accessibles. Nombre de ces changements en sont la conséquence. |
|
| |
|
|
| |
|
| ==DRBD== | | =[[LINUX:Loadbalancing - Router de répartition (masq)|Router de répartition]]= |
| Le système utilisé est Drbd. Classiquement ce système est utilisé en mode Actif/Passif (Primary/Secondary); il n'y a que la partie active qui peut avoir un accès à cette ressource disque. Dans cette configuration de deux machines actives, il faut que ces accès disques soient actifs des deux côtés ou Primary/Primary.
| | Ce router aura pour tâche de rediriger et de répartir les requêtes venant des clients en fonction des disponibilités des serveurs du cluster. Nous utilisons la configuration "Masquerading de NAT". |
| | |
| En outre, nous sommes revenus à des partitions de base de type Linux sans utilisation de LVM. Le schéma d'initialisation des disques et de la ressource Drbd est similaire à celle faite dans les articles sur le [[LINUX:Partitionnement du disque|Partitionnement du disque]] et [[LINUX:Drbd|Drbd]] mais sans la couche LVM. Les raisons sont doubles: montrer que cette autre initialisation plus ancienne est possible et de ne pas se soucier des problèmes de LVM dans le contexte d'une ressource disque partagée entre deux machines.
| |
| | |
| | |
| Le fichier de configuration "/etc/drbd.d/data.res" devient:
| |
| ----
| |
| resource drbddata {
| |
|
| |
| net {
| |
| protocol C;
| |
| verify-alg sha1;
| |
| '''allow-two-primaries yes ;'''
| |
| after-sb-0pri discard-zero-changes;
| |
| after-sb-1pri discard-secondary;
| |
| after-sb-2pri disconnect;
| |
| }
| |
|
| |
| '''startup { become-primary-on both; }'''
| |
|
| |
| disk {
| |
| on-io-error detach;
| |
| }
| |
|
| |
| handlers {
| |
| split-brain "/usr/lib/drbd/notify-split-brain.sh root";
| |
| out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
| |
| }
| |
|
| |
| on fo1.home.dom {
| |
| '''disk /dev/sdb1''';
| |
| address ipv4 192.168.2.71:7789;
| |
| device /dev/drbd1 minor 1;
| |
| meta-disk internal;
| |
| }
| |
|
| |
| on fo2.home.dom {
| |
| '''disk /dev/sdb1''';
| |
| address ipv4 192.168.2.72:7789;
| |
| device /dev/drbd1 minor 1;
| |
| meta-disk internal;
| |
| }
| |
| }
| |
| ----
| |
| Les deux options: "allow-two-primaries yes ;" et "startup { become-primary-on both; }" permettent et démarrent le système en mode "Primary/Primary".
| |
| Les devices disque de base sont ici tous deux "/dev/sdb1".
| |
| | |
| | |
| ==Formatage disque==
| |
| Auparavant nous avions formaté ce nouveau device en "XFS". Dans de cas-ci, il faut un système qui permettent un accès concurrent entre deux machines. Nous avons opté pour le formatage "GFS2". Il en existe un autre connu: "OCFS2".
| |
| | |
| Nous avons besoin d'installer de deux paquets spécifiques:
| |
| dnf install gfs2-utils
| |
| dnf install dlm
| |
| Le premier les utilitaires de formatage et d'utilisation de "GFS2"; le second est nécessaire pour gérer à travers le réseau la gestion concurrente de accès des disques spécialement en cas de modifications; une modification ne pouvant être effectuée que par un programme à la fois, chacun à son tour. Nous aurons donc besoin de lancer un service spécifique apporté par ce paquet.
| |
| | |
| | |
| Dès que la ressource "drbddata" de Drbd est prête, on choisit une machine et on met cette ressource à l'état actif avec la commande suivante:
| |
| drbdadm primary drbddata
| |
| Ceci fait, on formate le device "/dev/drbd1":
| |
| mkfs.gfs2 -p lock_dlm -j 2 -t fo_cluster:datacluster /dev/drbd1
| |
| Explications de quelques paramètres:
| |
| * -j 2 : on choisit deux journaux car nous avons deux disques partagés
| |
| * -t '''fo_cluster''':datacluster : la partie "fo_cluster" doit correspondre au nom du cluster repris dans la configuration de Corosync "/etc/corosync/corosync.conf":
| |
| ----
| |
| cluster_name: '''fo_cluster'''
| |
| ----
| |
| L'exécution de cette commande donne:
| |
| ----
| |
| This will destroy any data on /dev/drbd1
| |
| Are you sure you want to proceed? [y/n] y
| |
| Discarding device contents (may take a while on large devices): Done
| |
| Adding journals: Done
| |
| Building resource groups: Done
| |
| Creating quota file: Done
| |
| Writing superblock and syncing: Done
| |
| Device: /dev/drbd1
| |
| Block size: 4096
| |
| Device size: 149,04 GB (39070542 blocks)
| |
| Filesystem size: 149,04 GB (39070538 blocks)
| |
| Journals: 2
| |
| Journal size: 128MB
| |
| Resource groups: 598
| |
| Locking protocol: "lock_dlm"
| |
| Lock table: "fo_cluster:datacluster"
| |
| UUID: 4205aec6-99e4-4019-b150-aec81a885d12
| |
| ----
| |
| | |
| | |
| ==Paramétrage de Corosync==
| |
| Comme signalé ci-dessous, cette ressource disque qui utilise le service "dlm.service", doit être accessible en même temps sur l'autre machine. On ne peut travailler en Failover.
| |
| C'est à dire que le quorum doit être de '''deux''' et non comme dans le cas du Failover où ce quorum pouvait être de un.
| |
| | |
| | |
| Dans le fichier "/etc/corosync/corosync.conf", l'option "two_node: 1" doit être éliminée.
| |
| Eventuellement on peut la remplacer par "expected_votes: 2". La section "quorum" devient:
| |
| ----
| |
| quorum {
| |
| provider: corosync_votequorum
| |
| expected_votes: 2
| |
| }
| |
| ----
| |
| Pour devenir actif, il faut redémarrer le service Corosync.
| |
| | |
| Ces opérations doivent être faites sur les deux machines du cluster.
| |
| | |
| '''ATTENTION:''' Avant de redémarrer ce service Corosync, il faut démonter le disque Drbd
| |
| umount /data
| |
| car en arrêtant le service Corosync, celui de Dlm s'arrête également et comme le service Dlm est nécessaire, vous risquez fortement d'avoir des problèmes.
| |
| | |
| | |
| ==Configurer le mur de feu ou FireWall==
| |
| Si vous activez le Firewall, ce qui est recommandé, il faut y ajouter les règles suivantes:
| |
| * sur la machine "fo1.home.dom", on ajoute:
| |
| ----
| |
| -A INPUT -p tcp -m tcp --sport 21064 -s 192.168.3.72 -m conntrack --ctstate NEW -j ACCEPT
| |
| -A OUTPUT -p tcp -m tcp --dport 21064 -d 192.168.3.72 -j ACCEPT
| |
| ----
| |
| * sur la machine "fo2.home.dom", on ajoute:
| |
| ----
| |
| -A INPUT -p tcp -m tcp --sport 21064 -s 192.168.3.71 -m conntrack --ctstate NEW -j ACCEPT
| |
| -A OUTPUT -p tcp -m tcp --dport 21064 -d 192.168;3.71 -j ACCEPT
| |
| ----
| |
| Dès que le disque "/data" est monté, le service Dlm utilise un port TCP 2164 pour effectuer son travail.
| |
| | |
| | |
| ==Montage de "/data"==
| |
| On peut essayer de monter cette espace disque mais auparavant il est impératif de lancer le service Corosync:
| |
| systemctl start corosync.service
| |
| et de lancer le service de gestion des accès concurrents des disques:
| |
| systemctl start dlm.service
| |
| Ces deux services devront être lancés sur les deux machines du cluster.
| |
| | |
| Si vous ne le faites pas, le montage ne se fera pas et restera bloqué et ne pourra pas être tué; il ne vous restera que la solution que le redémarrage de la machine
| |
| | |
| La ressource "drbddata" devra être dans l'état "Primary/Primary" sur les deux machines du cluster
| |
| | |
| | |
| Le montage s'effectue avec la commande suivante, similaire à celle déjà vue excepté le type de formatage:
| |
| mount -t gfs2 /dev/drbd1 /data
| |
| On peut le faire sur les deux machines.
| |
| | |
| On peut en profiter pour recopier dans ce répertoire "/data", les sous-répertoires "web" et "home" utilisés dans l'article sur sur le [[LINUX:Pacemaker - Paramétrage des services en Failover|Paramétrage des services en Failover]].
| |
| | |
| | |
| | |
| | |
| | |
| | |
|
| |
|
|
| |
|
→ retour au menu de la Haute disponibilité
But
Toute autre approche, au lieu qu'un des serveurs soit en attente sans rien faire, les serveurs se répartissent la charge et se partagent les données. Une des machines est chargée de faire le partage équitablement. En anglais, on parle de Loadbalancing. Nous utilisons la configuration "Masquerading de NAT".
Principe
La configuration est proche de celle présentée dans l'article sur les Serveurs en Failover. Comme présentée sur le schéma ci-dessous, les deux serveurs sont presque identiques à l'article précédent excepté quelques détails. Par contre l'adresse virtuelle "192.168.1.73" et le nom virtuel "cluster.home.dom" est transporté sur une troisième machine qui joue le rôle de router et comme répartiteur de charge. Il repère les services actifs sur les serveurs du cluster et, en fonction de quotas, renvoie les requêtes des clients vers un serveur qui a le moins de travail.
Pour cette mise en place, deux grandes parties sont à considérer:
- la configuration des deux serveurs qui vont travailler de concert.
- la configuration du router qui aura la tâche de rediriger et répartir les requêtes des clients.
Prérequis
Configurations de départ
On démarre avec les configurations présentées lors de l'article sur les Serveurs en Failover. Quelques adaptations y seront apportée.
L'adressage doit correspondre au schéma ci-dessus.
Fichier "hosts"
Sur chaque machine du cluster, on ajoute un nom aux différentes adresses réseaux. On le fait en local dans le fichier "/etc/hosts" suivant le schéma ci-dessus. Son contenu devient:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.73 cluster.home.dom cluster
192.168.3.1 lb3.home.dom lb3
192.168.3.71 fo1.home.dom fo1
192.168.3.72 fo2.home.dom fo2
192.168.2.71 fd1.data.dom fd1
192.168.2.72 fd2.data.dom fd2
192.168.1.100 serverdb.home.dom serverdb home.dom
L'adresse IP "192.168.1.73" du router et son nom de machine associé "cluster.home.dom" sont cruciales pour la suite. C'est ce nom qui servira pour les clients pour interroger les serveurs du cluster.
Pour cette configuration, plusieurs pièces la composent et vont subir quelques transformations par rapport à l'article sur les Serveurs en Failover. Pour pouvoir utiliser une ressource disque partagée par deux machines en accès total, il faut changer de système de formatage. Or le système choisi nécessite que les deux espaces soient accessibles. Nombre de ces changements en sont la conséquence.
Ce router aura pour tâche de rediriger et de répartir les requêtes venant des clients en fonction des disponibilités des serveurs du cluster. Nous utilisons la configuration "Masquerading de NAT".
→ retour au menu de la Haute disponibilité