LINUX:Pacemaker - ISCSI en Failover
→ retour au menu de la Haute disponibilité
But
Si à la configuration précédente, nous ajoutons un client Initiator, nous pouvons passer à une installation en Failover utilisant des disques ISCSI. Cette configuration peut être facilement étendue au niveau des clients ISCSI de fonctionnalités de services WEB et de messagerie comme exposé dans l'article sur les Serveurs en Failover.
Matériel et adressage IP
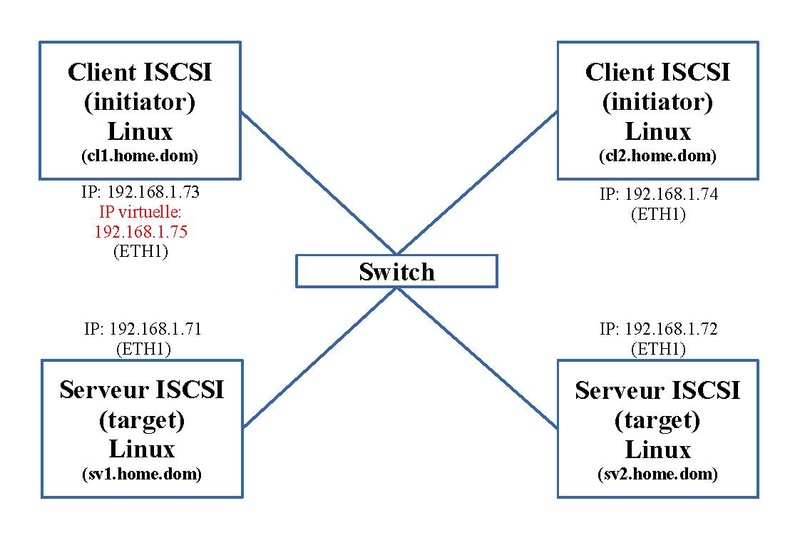
Dans notre exemple, nous utilisons deux serveurs ("target") et deux clients ("initiator"). Le schéma ci-dessous nous montre l'adressage IP et le nom de ces quatre machines. En outre pour mettre la fonction Failover, une adresse IP virtuelle est ajoutée. Elle passera d'un client ISCSI à l'autre.
Prérequis
Configurations de base
En premier, les Prérequis doivent être effectués.
Fichier "hosts"
Sur chaque machine du cluster, on ajoute un nom aux différentes adresses réseaux. On le fait en local dans le fichier "/etc/hosts" suivant le schéma ci-dessus. Son contenu devient:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.1.71 sv1.home.dom 192.168.1.72 sv2.home.dom 192.168.1.73 cl1.home.dom 192.168.1.74 cl2.home.dom 192.168.1.75 cluster.home.dom # serveur mail 192.168.1.110 servermail.home.dom home.dom
ISCSI
Nous nous baserons sur la configuration de l'article sur ISCSI à part qu'on double le client Initiator. Mais les services "tgtd.service" sur les serveurs Target ne sont pas lancés et le service "iscsi.service" ainsi que les montages des disques ISCSI "/datab" et "/datac" (fichier "/etc/fstab") sur les clients Initiator ne sont pas lancés. C'est Pacemaker qui s'en chargera.
En outre, comme nous avons ici deux clients au lieu d'un, il faut ajouter la ligne suivante dans le fichier "/etc/tgt/conf.d/diskb.conf" sur les deux machines "sv1.home.dom" et "sv2.home.dom". Elle permet à la machine "cl2.home.dom" d'accéder aux espaces ISCSI chacun avec son propre "initiator-name".
initiator-name iqn.2023-02.dom.home.sv:sv.initiator02 initiator-address 192.168.1.74
De plus, sur la machine client "cl2.home.dom" (Initiator), le fichier "/etc/iscsi/initiatorname.iscsi" contient le second InitiatorName introduit sur les machines serveurs ISCSI (target):
InitiatorName=iqn.2023-02.dom.home.sv:sv.initiator02
Sur la machine client "cl1.home.dom" (Initiator), ce même fichier reste inchangé:
InitiatorName=iqn.2023-02.dom.home.sv:sv.initiator01
Configuration de base
La Configuration de base de Pacemaker doit être effectuée avec quelques modifications car nous avons quatre machines dans le cluster au lieu de deux. Quelques modifications seront apportées ensuite. Nous allons passer rapidement en revue ces opérations.
Opérations locales
Sur chaque machine:
- le mot de passe de l'utilisateur "hacluster" est à implémenter. "Chasse4321Eau" pour mémoire.
- le service "pcsd.service" est à configurer et est lancé.
Initialisation du cluster
Pour initialiser le cluster, on effectue ces opérations sur une seule machine du cluster:
pcs host auth sv1.home.dom sv2.home.dom cl1.home.dom cl2.home.dom -u hacluster -p Chasse4321Eau pcs cluster setup fo_cluster \ sv1.home.dom addr=192.168.1.71 sv2.home.dom addr=192.168.1.72 cl1.home.dom addr=192.168.1.73 cl2.home.dom addr=192.168.1.74 \ transport knet ip_version=ipv4 link transport=udp mcastport=5420
Calcul du quorum
Si un des deux serveurs Target est indisponible, le disque SCSI sur le client Initiator actif doit être arrêté pour éviter tout blocage et si ce disque est indisponible, des fonctions du client sont aussi perturbées. L'ensemble du système est à arrêter. Par contre, si un des clients est arrêté, les services basculent sur l'autre client ISCSI et tout le système continue à fonctionner.
Ce problème se résume au calcul du quorum.
Par défaut, chaque machine a un vote; ce qui nous fait au total, quatre votes disponibles.
Un autre paramètre important est le nombre de votes souhaités ou "expected_votes". Par défaut il correspond au nombre total de votes apportés par les machines du cluster.
Le "quorum" se calcule de la façon suivante. On divise le paramètre "expected_votes" par deux; on en prend la partie entière auquel on ajoute une unité.
Dans notre situation, le quorum:
(4 votes)/2 + 1 = 3
Or nous sommes en présence d'une situation mixte; Si un des serveurs ISCSI s'arrête, les ressources de Pacemaker s'arrêtent et si un des clients ISCSI s'arrête, les ressources de Pacemaker se transfèrent sur l'autre client ISCSI.
Pour y arriver, nous allons passer par deux étapes:
- nous attribuons 2 votes à chaque serveur ISCSI
- nous attribuons 1 vote à chaque client ISCSI
- le nombre de votes souhaités est mis à 8
Le calcul du quorum devient:
(8 votes souhaités)/2 + 1 = 5
Voyons les deux cas de figure:
- Si un client ISCSI s'arrête, le nombre total de votes est de 5 (2*2 votes des serveurs ISCSI + 1 vote de l'autre client ISCSI). Le quorum est maintenu et les ressources de Pacemaker basculent vers l'autre client ISCSI.
- Si par contre un serveur ISCSI s'arrête, le nombre total de votes est de 4 (2 votes de l'autre serveur ISCSI + 2*1 votes des clients ISCSI). Le quorum n'est pas atteint et les ressources de Pacemaker s'arrêtent.
Modification de la configuration de Corosync
Pour atteindre ce quorum, il faut adapter sur chaque machine du cluster, le fichier "/etc/corosync/corosync.conf". La dernière commande a créé ce fichier. Dans la section "quorum", on va ajouter l'option "expected_votes: 8" et dans la sous-section "node" des serveurs ISCSI, on ajoute l'option "quorum_votes: 2".
Ce fichier devient:
totem {
version: 2
cluster_name: fo_cluster
transport: knet
ip_version: ipv4
crypto_cipher: aes256
crypto_hash: sha256
cluster_uuid: 678de5645057479a8b2c99180f3b3133
interface {
knet_transport: udp
linknumber: 0
mcastport: 5420
}
}
nodelist {
node {
ring0_addr: 192.168.1.71
name: sv1.home.dom
nodeid: 1
quorum_votes: 2
}
node {
ring0_addr: 192.168.1.72
name: sv2.home.dom
nodeid: 2
quorum_votes: 2
}
node {
ring0_addr: 192.168.1.73
name: cl1.home.dom
nodeid: 3
quorum_votes: 1
}
node {
ring0_addr: 192.168.1.74
name: cl2.home.dom
nodeid: 4
quorum_votes: 1
}
}
quorum {
provider: corosync_votequorum
expected_votes: 8
}
logging {
to_logfile: yes
logfile: /var/log/cluster/corosync.log
to_syslog: yes
timestamp: on
}
Lancement du cluster
Pour lancer l'ensemble, on exécute les commandes suivantes à partir d'une seule machine:
pcs cluster enable --all pcs cluster start --all
On n'oublie pas d'activer les trois services sur les quatres machines du cluster:
systemctl enable pcsd.service corosync.service pacemaker.service
Fin de la configuration
Par la même occasion exécutez la fin de la configuration de base:
pcs property set stonith-enabled=false pcs property set no-quorum-policy=stop
La dernière spécifie que si le quorum n'est pas atteint, les ressources de Pacemaker sont arrêtées.
Vérification du quorum
Sur chaque machine, exécutez cette commande:
pcs status corosync
qui donne:
Quorum information
------------------
Date: Wed Mar 1 17:11:22 2023
Quorum provider: corosync_votequorum
Nodes: 4
Node ID: 1
Ring ID: 1.7d
Quorate: Yes
Votequorum information
----------------------
Expected votes: 8
Highest expected: 8
Total votes: 6
Quorum: 5
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
1 2 sv1.home.dom (local)
2 2 sv2.home.dom
3 1 cl1.home.dom
4 1 cl2.home.dom
Si ce n'est pas le cas sur un machine, redémarrez y les trois services:
systemctl restart pcsd.service corosync.service pacemaker.service
Configuration des ressources
Script
On effectue la suite des commandes suivantes à partir d'une des machines du cluster. On peut les mettre dans un script.
#!/bin/bash pcs resource create ClusterTgtd1 systemd:tgtd op monitor interval=30s pcs constraint location ClusterTgtd1 prefers cl1.home.dom=-INFINITY pcs constraint location ClusterTgtd1 prefers cl2.home.dom=-INFINITY pcs constraint location ClusterTgtd1 prefers sv1.home.dom=INFINITY pcs constraint location ClusterTgtd1 prefers sv2.home.dom=-INFINITY pcs resource create ClusterTgtd2 systemd:tgtd op monitor interval=30s pcs constraint location ClusterTgtd2 prefers cl1.home.dom=-INFINITY pcs constraint location ClusterTgtd2 prefers cl2.home.dom=-INFINITY pcs constraint location ClusterTgtd2 prefers sv1.home.dom=-INFINITY pcs constraint location ClusterTgtd2 prefers sv2.home.dom=INFINITY pcs resource create ClusterIscsid systemd:iscsi op monitor interval=30s #pcs constraint location ClusterIscsid prefers cl1.home.dom=1000 #pcs constraint location ClusterIscsid prefers cl2.home.dom=100 pcs constraint location ClusterIscsid prefers sv1.home.dom=-INFINITY pcs constraint location ClusterIscsid prefers sv2.home.dom=-INFINITY pcs constraint order ClusterTgtd1 then start ClusterIscsid pcs constraint order ClusterTgtd2 then start ClusterIscsid pcs resource create ClusterIP ocf:heartbeat:IPaddr2 ip=192.168.1.75 nic=eth1 cidr_netmask=24 iflabel=ethcl1 lvs_support=true op monitor interval=30s #pcs constraint location ClusterIP prefers cl1.home.dom=1000 #pcs constraint location ClusterIP prefers cl2.home.dom=100 pcs constraint location ClusterIP prefers sv1.home.dom=-INFINITY pcs constraint location ClusterIP prefers sv2.home.dom=-INFINITY pcs constraint colocation add ClusterIP with ClusterIscsid score=INFINITY pcs constraint order ClusterIscsid then start ClusterIP pcs resource create ClusterMailTo ocf:heartbeat:MailTo email=root subject="FailOver_Home" op monitor interval=30s #pcs constraint location ClusterMailTo prefers cl1.home.dom=1000 #pcs constraint location ClusterMailTo prefers cl2.home.dom=100 pcs constraint location ClusterMailTo prefers sv1.home.dom=-INFINITY pcs constraint location ClusterMailTo prefers sv2.home.dom=-INFINITY pcs constraint colocation add ClusterMailTo with ClusterIscsid score=INFINITY pcs constraint order ClusterIP then start ClusterMailTo pcs resource create ClusterFsDatab ocf:heartbeat:Filesystem \ device="/dev/disk/by-uuid/74435bdf-f453-471f-aa85-ec5418d59cfd" \ directory="/datab" fstype="xfs" \ "options=defaults,_netdev" \ op monitor interval=20s on-fail=stop #pcs constraint location ClusterFsDatab prefers cl1.home.dom=1000 #pcs constraint location ClusterFsDatab prefers cl2.home.dom=100 pcs constraint location ClusterFsDatab prefers sv1.home.dom=-INFINITY pcs constraint location ClusterFsDatab prefers sv2.home.dom=-INFINITY pcs constraint colocation add ClusterFsDatab with ClusterIscsid score=INFINITY pcs constraint order ClusterIP then start ClusterFsDatab pcs resource create ClusterFsDatac ocf:heartbeat:Filesystem \ device="/dev/disk/by-uuid/c45eb09d-3eae-4090-995f-3da5ab7d167c" \ directory="/datac" fstype="xfs" \ "options=defaults,_netdev" \ op monitor interval=20s on-fail=stop #pcs constraint location ClusterFsDatac prefers cl1.home.dom=1000 #pcs constraint location ClusterFsDatac prefers cl2.home.dom=100 pcs constraint location ClusterFsDatac prefers sv1.home.dom=-INFINITY pcs constraint location ClusterFsDatac prefers sv2.home.dom=-INFINITY pcs constraint colocation add ClusterFsDatac with ClusterIscsid score=INFINITY pcs constraint order ClusterIP then start ClusterFsDatac
Ajout des ressources Tgtd
Ces deux premiers blocs créent les ressources "ClusterTgtd1" et "ClusterTgtd2" qui lancent le service "tgtd.service" sur les serveurs Target. Les contraintes de localisation imposent d'une part que cette ressource soit lancée sur chaque machine serveur Target ("INFINITY"); la ressource "ClusterTgtd1" est lancée sur la machine "sv1.home.dom" et la ressource "ClusterTgtd2" est lancée sur la machine "sv2.home.dom". D'autre part, la ressource concernée ne se lance pas sur l'autre serveur Target ni sur les client Initiator "cl1.home.dom" et "cl2.home.dom" ("-INFINITY").
Ajout de la ressource Iscsi
De la même façon, le service "iscsi.service" est initié par la ressource "ClusterIscsid" qui ne peut être localisé que sur une des machines Initiator "cl1.home.dom" ou "cl2.home.dom". Cette ressource ne sera lancée qu'après que les ressources lançant la partie serveur ISCSI Target soient lancée. En commentaire, les contraintes de préférence permettent, si on enlève les commentaires de préférer la machine "cl1.home.dom" si elle est active.
Ajout de la ressource de l'adresse IP virtuelle
Vient ensuite la création de notre ressource "ClusterIP" en suivant la fonction déjà rencontrée "ocf:heartbeat:IPaddr2" que nous attribuons à la machine active "cl1.home.dom" ou "cl2.home.dom". En commentaire, nous retrouvons les mêmes contraintes de préférence que ci-dessus.
Ajout de la ressource de notification par mail
Vient ensuite la création de notre ressource "ClusterMailTo" traditionnelle que nous attribuons à la machine active "cl1.home.dom" ou "cl2.home.dom". En commentaire, nous retrouvons les mêmes contraintes de préférence que ci-dessus.
Ajout des ressources disques ISCSI
Enfin viennent les deux blocs de création des ressources "ClusterDatab" et "ClusterDatac" qui vont monter les deux espaces disques ISCSI sur les répertoires "/datab" et "/datac". Elles utilisent la fonction "ocf:heartbeat:Filesystem" déjà rencontrée par le passé. On y retrouve les paramètres qui avaient été mis dans le fichier "/etc/fstab". Ces ressources ne seront localisées que sur la machine active "cl1.home.dom" ou "cl2.home.dom". Evidemment ces ressources ne peuvent être lancées qu'après la ressource "ClusterIscsid". En commentaire, nous retrouvons les mêmes contraintes de préférence que ci-dessus.
Colocation
Ces 5 dernières ressources se retrouvent ensemble.
Problèmes
Lors de l'exécution de ce script, quelques erreurs peuvent apparaître. Lors de la création des ressources, Pacemaker essaie de la lancer sur une machine; si ce lancement est impossible sur une machine car elle ne lui est pas destinée, non configurée, il y a erreur. Ceci se régularise dès la localisation est implémentée.
Il faut nettoyer ces erreurs. Voici un script général qui passe tout en revue:
#!/bin/bash pcs resource cleanup ClusterMailTo pcs resource cleanup ClusterIP pcs resource cleanup ClusterIscsid pcs resource cleanup ClusterTgtd1 pcs resource cleanup ClusterTgtd2 pcs resource cleanup ClusterFsDatab pcs resource cleanup ClusterFsDatac pcs stonith history cleanup sr1.home.dom pcs stonith history cleanup sr2.home.dom pcs stonith history cleanup cl1.home.dom pcs stonith history cleanup cl2.home.dom
Autre problème, lors de l'arrêt des machines juste après l'exécution, l'arrêt du service "pacemaker.service" bloque. Ce problème n'apparaî plus par la suite. Je conseille d'arrêter ces trois services au moins sur une machine lors de ce premier arrêt global:
systemctl stop pcsd.service corosync.service pacemaker.service
Notons qu'il y a des moyens de contourner ce problème au lieu de les exécuter en direct; ce que nous n'avons pas fait.
Statut
Après cette opération, l'état du cluster peut être visualisé par la commande:
crm_mon -1
qui donne dans le cas des trois machines actives:
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-03-10 21:16:52 +01:00) Cluster Summary: * Stack: corosync * Current DC: sv1.home.dom (version 2.1.5-3.fc37-a3f44794f94) - partition with quorum * Last updated: Fri Mar 10 21:16:52 2023 * Last change: Fri Mar 10 11:17:54 2023 by hacluster via crmd on cl1.home.dom * 4 nodes configured * 7 resource instances configured Node List: * Online: [ cl1.home.dom cl2.home.dom sv1.home.dom sv2.home.dom ] Active Resources: * ClusterTgtd1 (systemd:tgtd): Started sv1.home.dom * ClusterTgtd2 (systemd:tgtd): Started sv2.home.dom * ClusterIscsid (systemd:iscsid): Started cl1.home.dom * ClusterIP (ocf::heartbeat:IPaddr2): Started cl1.home.dom * ClusterMailTo (ocf::heartbeat:MailTo): Started cl1.home.dom * ClusterFsDatab (ocf::heartbeat:Filesystem): Started cl1.home.dom * ClusterFsDatac (ocf::heartbeat:Filesystem): Started cl1.home.dom
Et dans le cas où un des serveurs ISCSI est arrêté:
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-03-10 21:19:11 +01:00) Cluster Summary: * Stack: corosync * Current DC: sv1.home.dom (version 2.1.5-3.fc37-a3f44794f94) - partition WITHOUT quorum * Last updated: Fri Mar 10 21:19:11 2023 * Last change: Fri Mar 10 11:17:54 2023 by hacluster via crmd on cl1.home.dom * 4 nodes configured * 7 resource instances configured Node List: * Online: [ cl1.home.dom cl2.home.dom sv1.home.dom ] * OFFLINE: [ sv2.home.dom ] Active Resources: * No active resources
Dans ce second cas, la commande:
pcs status corosync
donne:
Quorum information
------------------
Date: Fri Mar 10 21:21:56 2023
Quorum provider: corosync_votequorum
Nodes: 3
Node ID: 1
Ring ID: 1.47
Quorate: No
Votequorum information
----------------------
Expected votes: 8
Highest expected: 8
Total votes: 4
Quorum: 5 Activity blocked
Flags:
Membership information
----------------------
Nodeid Votes Name
1 2 sv1.home.dom (local)
3 1 cl1.home.dom
4 1 cl2.home.dom
→ retour au menu de la Haute disponibilité