LINUX:Pacemaker - Configuration de base
→ retour au menu de la Haute disponibilité
But
Avant d'aborder des cas spécifiques de clusters, on passe d'office par une étape de configuration de base commune à tous les cas. Par la suite, quand on abordera notre cas spécifique de Loadbalancing, deux paramètres seront changés.
Matériel et adressage IP
Pour ces exercices, nous avons besoin de deux machines, chacune avec deux interfaces réseaux. Le schéma ci-dessous reprend la connectique, le nom des machines Linux et leur adressage IP.
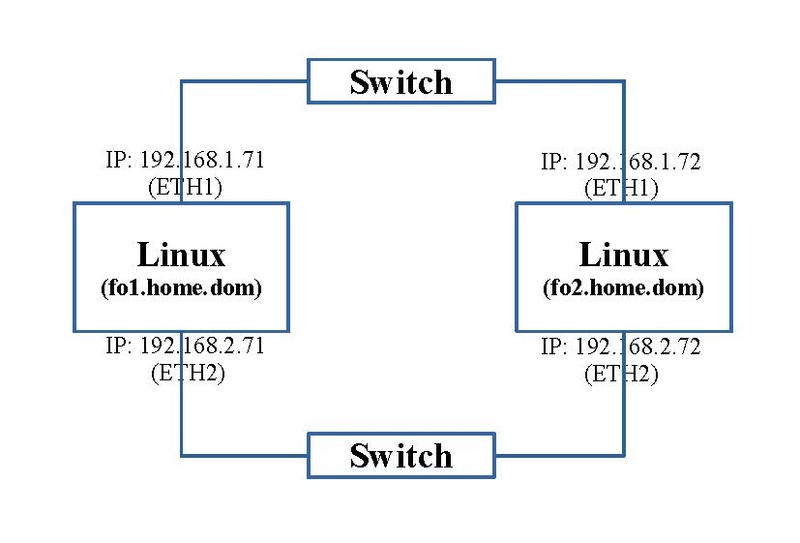
Prérequis
Uniformisation des noms des interfaces réseaux
Il est conseillé et dans une situation future, que les noms des interfaces réseaux soient uniformisés sur les différentes machines du cluster.
- Du côté du réseau "192.168.1.0/24", nous avons opté pour le nom "eth1".
- Du côté du réseau "192.168.2.0/24", nous avons opté pour le nom "eth2".
Pour effectuer cette tâche, voyez l'article traitant du Renommage du nom de l'interface réseau.
Selinux
Pour une question de facilité, nous désactivons la couche Selinux. Pour y arriver, on change la ligne suivante dans le fichier "/etc/selinux/config":
SELINUX=enforcing
par:
SELINUX=disabled
Fichier "hosts"
Sur chaque machine du cluster, on ajoute un nom aux différentes adresses réseaux. On le fait en local dans le fichier "/etc/hosts" suivant le schéma ci-dessus. Son contenu devient:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.1.71 fo1.home.dom 192.168.1.72 fo2.home.dom 192.168.2.71 fd1.data.dom 192.168.2.72 fd2.data.dom # serveur mail 192.168.1.110 servermail.home.dom home.dom
Pour nos exemples, les lignes 7 et 8 ne sont pas nécessaires car tout se passera pour cette phase par les interfaces "eth1".
Postfix
Dans tous les applications futures, on demandera à Pacemaker de nous avertit de l'état du cluster par mail. Il nous faut donc configurer Postfix au minimum pour transférer ce message à notre serveur de messagerie central "192.168.1.110" ayant le nom de domaine "home.dom". Voyez l'article Postfix-Configuration des serveurs de messagerie latérale et parents.
Voici le contenu du fichier "/etc/postfix/main.cf":
# nouveaux paramètres
relayhost = [192.168.1.110]
inet_protocols = ipv4
# paramètres par défaut
compatibility_level = 3.7
queue_directory = /var/spool/postfix
command_directory = /usr/sbin
daemon_directory = /usr/libexec/postfix
data_directory = /var/lib/postfix
mail_owner = postfix
inet_interfaces = localhost
mydestination = $myhostname, localhost.$mydomain, localhost
unknown_local_recipient_reject_code = 550
alias_maps = hash:/etc/aliases
alias_database = hash:/etc/aliases
debug_peer_level = 2
debugger_command =
PATH=/bin:/usr/bin:/usr/local/bin:/usr/X11R6/bin
ddd $daemon_directory/$process_name $process_id & sleep 5
sendmail_path = /usr/sbin/sendmail.postfix
newaliases_path = /usr/bin/newaliases.postfix
mailq_path = /usr/bin/mailq.postfix
setgid_group = postdrop
meta_directory = /etc/postfix
shlib_directory = /usr/lib64/postfix
Sur base de la configuration de base, on change deux paramètres.
Voici le contenu du fichier "/etc/postfix/main.cf":
# ========================================================================== # service type private unpriv chroot wakeup maxproc command + args # (yes) (yes) (no) (never) (100) # ========================================================================== pickup unix n - n 60 1 pickup cleanup unix n - n - 0 cleanup qmgr unix n - n 300 1 qmgr tlsmgr unix - - n 1000? 1 tlsmgr rewrite unix - - n - - trivial-rewrite bounce unix - - n - 0 bounce defer unix - - n - 0 bounce trace unix - - n - 0 bounce verify unix - - n - 1 verify flush unix n - n 1000? 0 flush proxymap unix - - n - - proxymap proxywrite unix - - n - 1 proxymap smtp unix - - n - - smtp showq unix n - n - - showq error unix - - n - - error retry unix - - n - - error discard unix - - n - - discard local unix - n n - - local lmtp unix - - n - - lmtp anvil unix - - n - 1 anvil scache unix - - n - 1 scache postlog unix-dgram n - n - 1 postlogd
La configuration par défaut est suffisante; nous avons éliminé tous les processus à l'écoute.
Enfin nous ajoutons à la fin du fichier "/etc/aliases", la ligne suivante:
root: adebast@home.dom
Tout message à destination de l'utilisateur "root" local sera redirigé vers l'utilisateur "adebast@home.dom".
Il reste à activer et lancer ce service:
systemctl enable postfix newaliases systemctl start postfix
Si vous avez activé le filtrage du firewall en sortie, ajoutez y cette ligne:
-A OUTPUT -p tcp -m tcp --dport 25 -d 192.168.1.110 -j ACCEPT
Configuration de Pcs sur toutes les machines du cluster
Toute la configuration va se passer à l'aide du programme en ligne de commande "pcs". En premier lieu, il faut initier ce cadre de travail sur toutes les machines du cluster afin qu'elles puissent communiquer.
Initialisation du mot de passe
Sur les deux machines du cluster, un utilisateur "hacluster" est créé. Il va servir au transfert d'informations sécurisé. Son utilisation est désactivé. Pour le rendre utilisable, il faut initialiser le mot de passe par la commande suivante:
passwd hacluster
Il demande le nouveau mot de passe et sa confirmation. Nous attribuerons le mot de passe: "Chasse4321Eau" (A adapter à votre convenance. Cette tâche est à effectuer sur chaque machine du cluster.
Service "pcsd.service"
Pour effectuer la configuration, on utilisera la commande de ligne "pcs" qui va transmettre nos ordres au service local "pcsd.service". Il va le transmettre aux services équivalent "pcsd.service" s'exécutant également sur les autres machines du cluster. Ce qui nous permettra de faire ces manipulation qu'à partir d'une seule machine.
Mais en premier lieu, nous désirons restreindre ce trafic à la couche IPV4. Dans le fichier de configuration de ce service "/etc/sysconfig/pcsd'", on ajoute la ligne:
PCSD_BIND_ADDR='0.0.0.0'
On remarque au passage, dans ce fichier, que le port d'écoute TCP de ce service est par défaut le 2224 ("PCSD_PORT=2224").
On peut maintenant lancer ce service:
systemctl start pcsd.service
Ces opérations sont à faire sur toutes les machines du cluster.
A ce stade, on peut constater qu'un nouveau port est à l'écoute. La commande suivante:
netstat -nltp | grep 2224
donne:
tcp 0 0 0.0.0.0:2224 0.0.0.0:* LISTEN 14864/python3
Configuration centralisée grâce à Pcs
Maintenant nous pouvons commencer la configuration de Pacemaker et de Corosync.
Définir les machines faisant partie du cluster
La commande suivante permet d'ajouter les machines qui vont converser ensemble:
pcs host auth fo1.home.dom fo2.home.dom -u hacluster -p Chasse4321Eau
Nous y trouvons le nom de nos deux machines. On y constate également notre utilisateur Unix "hacluster" et son mot de passe "Chasse4321Eau". Ces deux paramètres additionnels nous évitent que la commande ne nous les demande interactivement. Elle s'échange une clé sécurisée comme le protocole Ssh, pour pouvoir s'abstenir à l'avenir de devoir s'authentifier par le couple nom d'utilisateur/mot de passe.
Création du cluster
La commande suivante crée le cluster auquel nous avons donné de nom de "fo_cluster" et qui va inclure nos deux machines. Par la même occasion, Corosync va être configuré. Il utilisera le protocole crypté "knet" en utilisant le port UDP multicast 5420 sous IPV4.
pcs cluster setup fo_cluster fo1.home.dom addr=192.168.1.71 fo2.home.dom addr=192.168.1.72 transport knet ip_version=ipv4 link transport=udp mcastport=5420
Si vous avez plusieurs clusters qui cohabitent, donnez un n° de port différent. Le n° de port par défaut est 5405.
Fichier de configuration de Corosync
Notre action précédente a créé le fichier de configuration de Corosync "/etc/corosync/corosync.conf" dont voici le contenu:
totem {
version: 2
cluster_name: fo_cluster
transport: knet
ip_version: ipv4
crypto_cipher: aes256
crypto_hash: sha256
cluster_uuid: b7c29a052377490da9c146c33d671672
interface {
knet_transport: udp
linknumber: 0
mcastport: 5420
}
}
nodelist {
node {
ring0_addr: 192.168.1.71
name: fo1.home.dom
nodeid: 1
}
node {
ring0_addr: 192.168.1.72
name: fo2.home.dom
nodeid: 2
}
}
quorum {
provider: corosync_votequorum
two_node: 1
}
logging {
to_logfile: yes
logfile: /var/log/cluster/corosync.log
to_syslog: yes
timestamp: on
}
Vous y retrouvez les paramètres introduits par la commande "pcs" précédente (en gras).
Remarquez au passage le paramètre spécial "two_node: 1". Il est propre au cas d'un cluster composé de seulement deux machines. Normalement pour qu'un cluster puisse démarrer, il faut 50% des machines + 1, c'est à dire 2 ou 100% dans ce cas pour que le cluster démarre, si cette option n'est pas définie. Cette notion est connue sous le nom de "quorum". Ce paramètre permet d'outrepasser cette règle pour la ramener à 50% pour deux machines. Par défaut, chaque machine a une voie (ou vote). C'est ce nombre de voies actives qui est à comparer au nombre total de voies possible, et qui équivaut par défaut au nombre de machines du cluster, pour en définir le pourcentage actif.
Activation et lancement du cluster
Maintenant nous sommes fin prêts pour activer et démarrer le cluster par les deux commandes qui suivent:
pcs cluster enable --all pcs cluster start --all
Ces commandes lancent en fait sur toutes les machines du cluster les services "corosync.service" et "pacemaker.service" en plus du service "pcsd.service".
Maintenant que Corosync est lancé, la commande suivante sur la machine "fo1.home.dom":
netstat -nlup | grep 5420
donne:
udp 0 0 192.168.3.71:5420 0.0.0.0:* 28367/corosync
Et sur l'autre machine:
udp 0 0 192.168.3.72:5420 0.0.0.0:* 23585/corosync
On y remarque l'apparition du port UDF 5420 comme mis dans le fichier de configuration de Corosync.
Finalisation
Nous sommes avec une configuration limitée. Nous désactivons deux fonctions: une action en cas de "quorum" non atteint et une détection de déficience par une ressource tierce.
pcs property set no-quorum-policy=ignore pcs property set stonith-enabled=false
Emplacement des fichiers
Tout un ensemble de fichiers sont générés:
- les fichiers de configuration dans les répertoires suivants:
/etc/corosync /etc/pacemaker
- les journaux dans les répertoires suivants:
/var/log/pcsd /var/log/cluster /var/log/pacemaker
- les autres fichiers de configuration dans les répertoires suivants:
/var/lib/corosync /var/lib/pcsd /var/lib/pacemaker/cib /var/lib/pacemaker/pengine
Un fichier est particulier. Le fichier "/var/lib/pacemaker/cib/cib.xml" contient la configuration de Pacemaker mais ne vous avisez pas de le modifier manuellement. Il est protégé par une signature. Son contenu est instructif.
Pour repartir de zéro, il faut arrêter les trois services cités ci-dessus et effacer tous les fichiers de ces répertoires
Statut
On peut visionner l'état du cluster avec la commande suivante:
crm_mon -1
Cette commande peut être exécutée à partir de toute machine du cluster. Elle donne:
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-02-08 11:24:39 +01:00) Cluster Summary: * Stack: corosync * Current DC: fo1.home.dom (version 2.1.5-3.fc37-a3f44794f94) - partition with quorum * Last updated: Wed Feb 8 11:24:39 2023 * Last change: Wed Feb 8 11:24:34 2023 by root via cibadmin on fo1.home.dom * 2 nodes configured * 0 resource instances configured Node List: * Online: [ fo1.home.dom fo2.home.dom ] Active Resources: * No active resources
Le paramètre "-1" permet d'avoir un affichage unique. S'il n'est pas spécifié, l'affichage est perpétuel et se rafraichit régulièrement de façon similaire à la commande "top".
→ retour au menu de la Haute disponibilité